迎接智能体的「觉醒时刻」:EverOS全球公测开启Agent Memory自进化序章
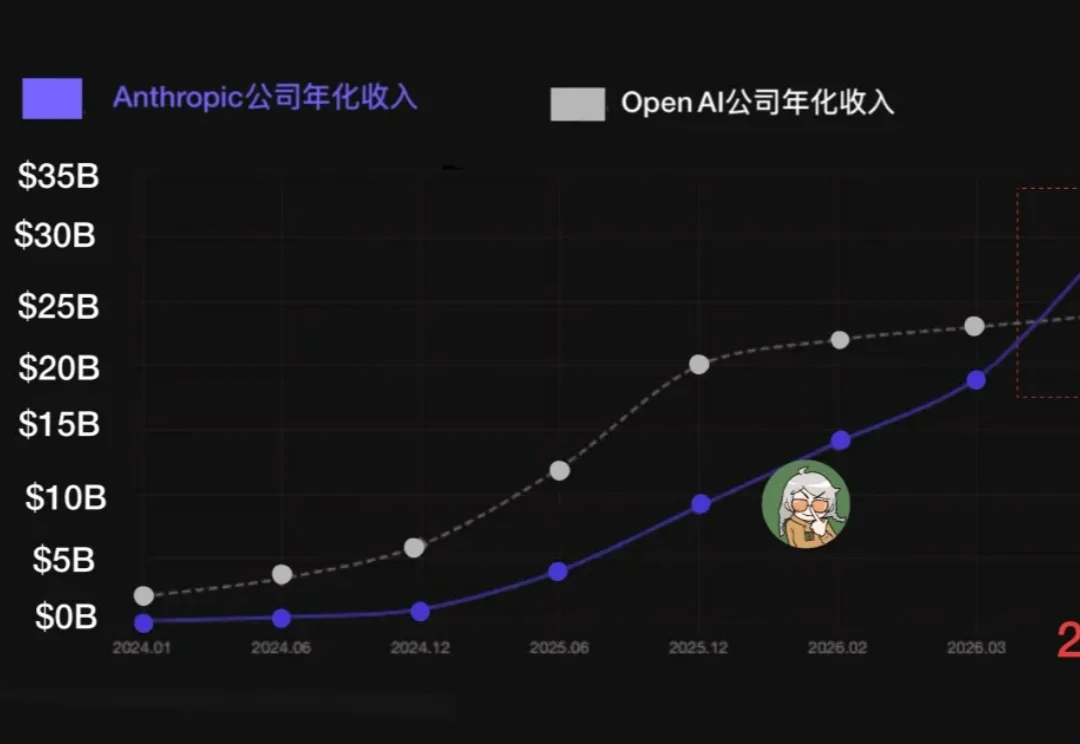
迎接智能体的「觉醒时刻」:EverOS全球公测开启Agent Memory自进化序章随着新一代主动执行型 Agent(如 OpenClaw、Hermes Agent 等)的爆发,AI 正经历从「被动工具」向「具备自我演化(Self-Evolving)能力的智能体」的范式跃迁。然而,受限于上下文窗口极限与记忆缺失,现有 Agent 难以在复杂任务中实现经验的复用与自我进化。
来自主题: AI技术研报
7943 点击 2026-04-15 10:07